ChatGPT ushered in a new era of consciousness for large language models (LLMs) with two important contributions: 1) a ubiquitous user experience and 2) using humans to remove some of the charged content in input data that LLMs have been criticized for.
Although there has been robust debate on their efficacy, the effectiveness (accuracy) of LLMs, in general, has been improving based on their size, which has increased by orders of magnitude with each release. This has been proven by ChatGPT’s generation capabilities in predicting the next word, then the next word, then the next word, and on and on and on… The larger the LLM, the greater the population of data to use in its ability to predict. So, with 175B parameters for GPT-3.5 (the LLM initially behind ChatGPT), we have seen that LLMs can do a decent job of Natural Language Generation (NLG). But is bigger better?
Challenges for Toxicity, Privacy and Governance
If you consider ChatGPT the coming out party for the widespread, public use of LLMs, it is no surprise that, while its capabilities were initially met with amazement, this soon turned to caution.
This was no surprise to those of us who were familiar with LLMs prior to ChatGPT’s release. There has never been a shortage of debate about their potential value as well as the toxicity LLMs are capable of eliciting. But with the introduction of ChatGPT, for the first time, an LLM became a targeted consumer application and soon amazement gave way to concern.
Initially, concerns were centered on how ChatGPT was used; plagiarism, accuracy and the recency of the data set were the front and center issues. However, with more time and scrutiny, focus shifted, appropriately, to the content being created. “Hallucinations” and toxicity, the latter of which has always existed in the LLM world, started to become the main areas of concern. Again, some of these were reduced via human review but not eliminated, given the size of GPT.
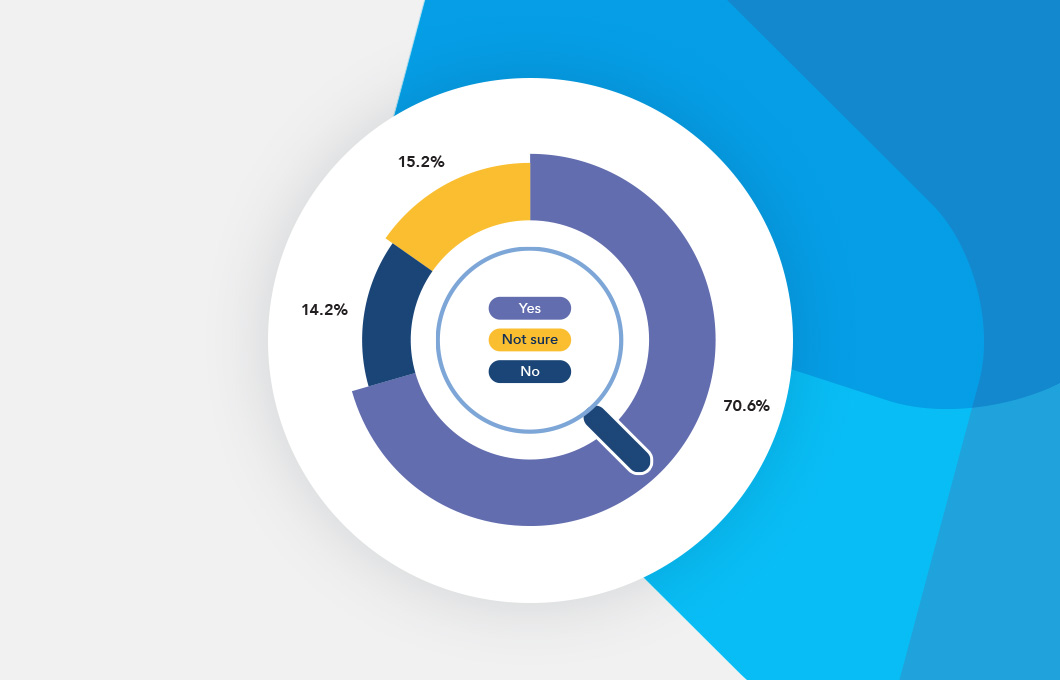
In our own survey of more than 300 business, technical and academic natural language AI experts, lack of truthfulness (69.8%) was the top ethical and legal concern around LLMs, followed by biased output (67.3%) and the risk of proprietary data leaks (62.6%).

The heightened attention has raised consciousness and created even greater attention within the enterprise. where a host of possibilities are being discussed and contemplated. The possibilities seemed boundless, but amidst that excitement another concern that has always surrounded LLMs (and enterprises in general) was temporarily shelved: governance.
Concerns around the personal data and copyrighted material contained in LLMs like GPT-3 led to an outright ban in Italy and close scrutiny from data protection authorities in Canada, the European Union and China. As the debate about how to manage and regulate these technologies continues, companies have to take these risks into consideration when they consider bringing applications like ChatGPT and LLMs into the enterprise.
Amidst the excitement and caution, we are seeing how and where LLMs can play in the enterprise space. Yes, there is risk, but when risk can be reasonably managed, there is undoubtedly high potential and, like any natural language AI capability, the potential for high payoff. But again, a quick reminder before we set off…the risk must be managed. Here are some ways to do it.
Four Scenarios to Reduce Enterprise Risk with LLMs
1. Start with a Specific Domain
One of the ways that enterprises can use LLMs to their advantage while reducing time to value and costs is by focusing it to provide specific information within a domain.
Domains have their own language, terms and jargon. For most enterprises, it’s not necessary to understand the specialized terminology used in every domain, but it is critically important to understand your specific domain with great precision.
Think of the specialized terms used in insurance, financial services, life sciences & pharmaceuticals, manufacturing and others. Then think of the very precise terms used within a subdomain, such as for assessing risk in insurance or processing a medical claim. These all have a high level of specificity that is absolutely critical to understand. One way to provide enterprise value with LLMs is by focusing them in a narrow, targeted area; this also reduces the compute cost of LLMs and makes their usage scalable.
2. Use a Hybrid Approach
Within the natural language arena, the potential for charged content created by the LLM approach has long been an area of debate. Proponents of alternative methodologies would argue against LLMs or machine learning approaches for this reason, and this became a sort of “religious debate” that resulted in an either/or approach.
Over the past few years, however, the thinking has evolved and now many AI solutions use multiple approaches. Data also shows that this is the path to the highest accuracy. So, the accepted approach today does not rely solely on LLMs but uses a Hybrid AI approach of LLMs in combination with machine learning and/or a rules-based approach.
3. Test Drive LLM Compression Techniques
Beyond a Hybrid AI approach, there are existing LLM compression techniques like pruning, quantization and knowledge distillation that can be used (sometimes in combination) to create domain focus for LLMs. At expert.ai, we have been exploring different techniques to leverage LLMs for our clients for several years now. The goals have been to push the envelope and determine the best way to leverage specific LLMs to save time, reduce costs and increase accuracy for our clients. Using LLMs along with traditional rules-based techniques, also known as the symbolic approach, yields the best results AND offers additional benefits like explainability and a smaller carbon footprint. Some interesting work that we have done on LLM compression for specific use cases has been published here.
4. Explore Practical Scenarios
Beyond researching new techniques, we have also created working solutions for many of our clients. This includes the European Space Agency, which you can learn about here, and in our research projects. Other projects in progress include using LLMs as part of the NL solution for enterprise search (in combination with elastic search integration), identifying relevant entities for automated handling of non-performing loans or policy comparison, and review, summarization and validation for medical claims.
Bigger Is Not Better
As the hype surrounding LLMs subsides, the reality of how they will play in the enterprise space is beginning to come into focus. New expert.ai research “Large Language Models: Opportunity, Risk and Paths Forward” shows that nearly 40% of enterprises are already planning to train and customize language models to meet their business needs.
OpenAI is already dialing back plans to make GPT even larger. And existing techniques like the ones we mention above are already available to augment ‘one size fits all, bigger is better’ thinking by integrating both longstanding and creative techniques to train these models to serve the specific domain needs of the enterprise. This, along with the integration of multiple approaches via hybrid AI, as acknowledged by the analyst community, will help mitigate the risks and other issues that enterprises currently face in driving the value that LLMs can provide.
As our CEO Walt Mayo recently commented, “Now the focus shifts to giving these small models domain relevance, the integrated workflows that put them to good effect, and building the security, scalability and performance needed for enterprise-grade software. Which happily is what we are doing at expert.ai.”
Contact us for more information on how expert.ai is using LLMs to create value in the enterprise.